Opus 4.6 ist da – und wir nutzen es ab sofort
Das intelligenteste Modell von Anthropic ist da. Was die Benchmarks sagen, was sich für unsere Kunden ändert, und warum wir ab sofort Opus 4.6 produktiv einsetzen.
Opus 4.6 ist da – und wir nutzen es ab sofort
Als ich gestern Abend die Ankündigung von Anthropic gelesen habe, musste ich erst mal durchatmen. Nicht wegen Marketing-Hype, sondern weil die Benchmark-Zahlen genau das bestätigen, was ich seit Wochen in der Beta gespürt habe: Claude Opus 4.6 ist ein anderes Level.
Ich arbeite jeden Tag mit Claude – für unsere internen Workflows, für Kunden-Agenten, für Code-Reviews. Und der Unterschied zu Opus 4.5 ist nicht inkrementell. Er ist spürbar. Weniger Nachfragen, bessere Erstantworten, und bei komplexem Code bleibt das Ding einfach dran.
Die Zahlen: Was Opus 4.6 wirklich kann
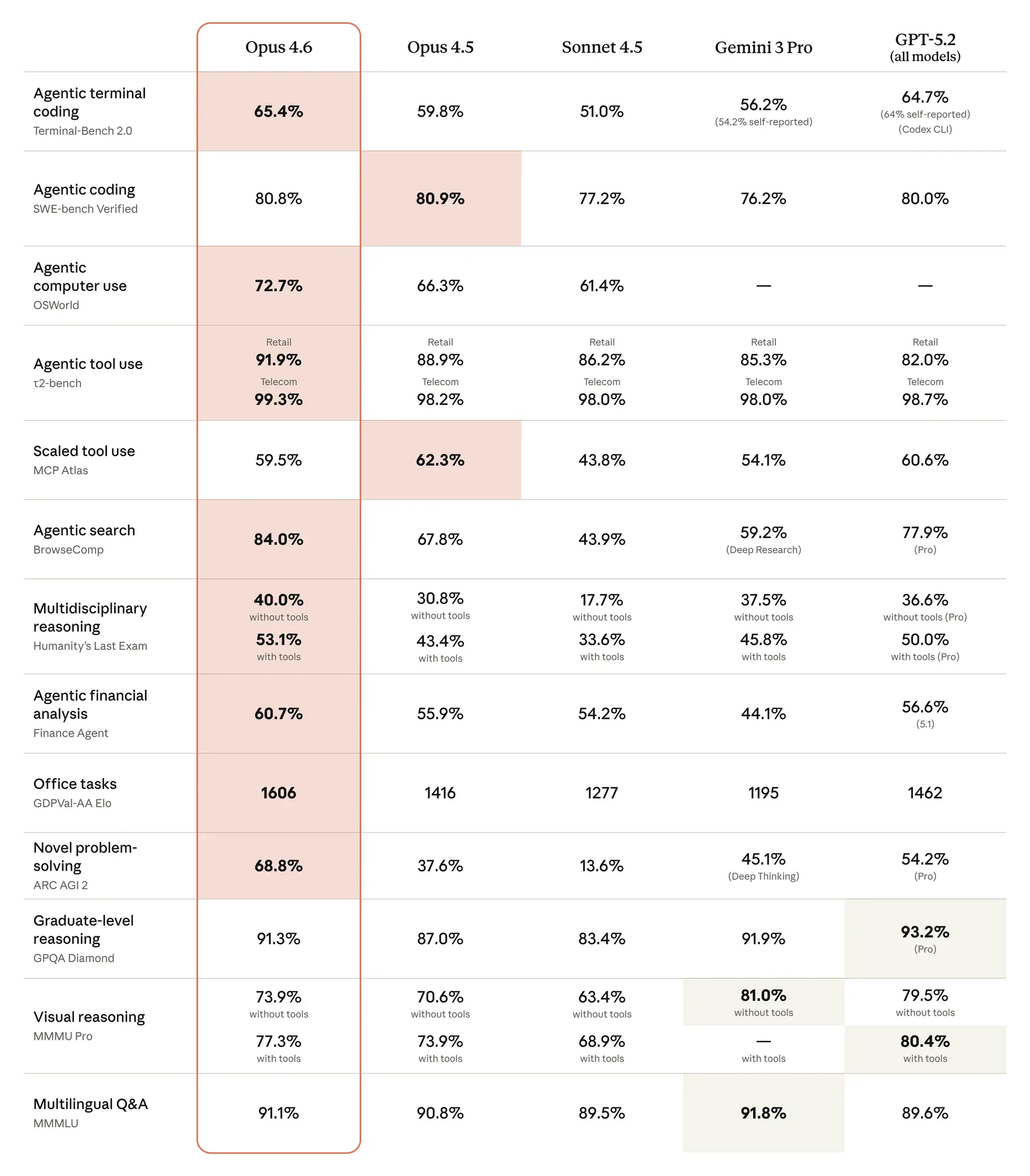
Zahlen lügen nicht. Hier sind die offiziellen Benchmarks von Anthropic im Vergleich:
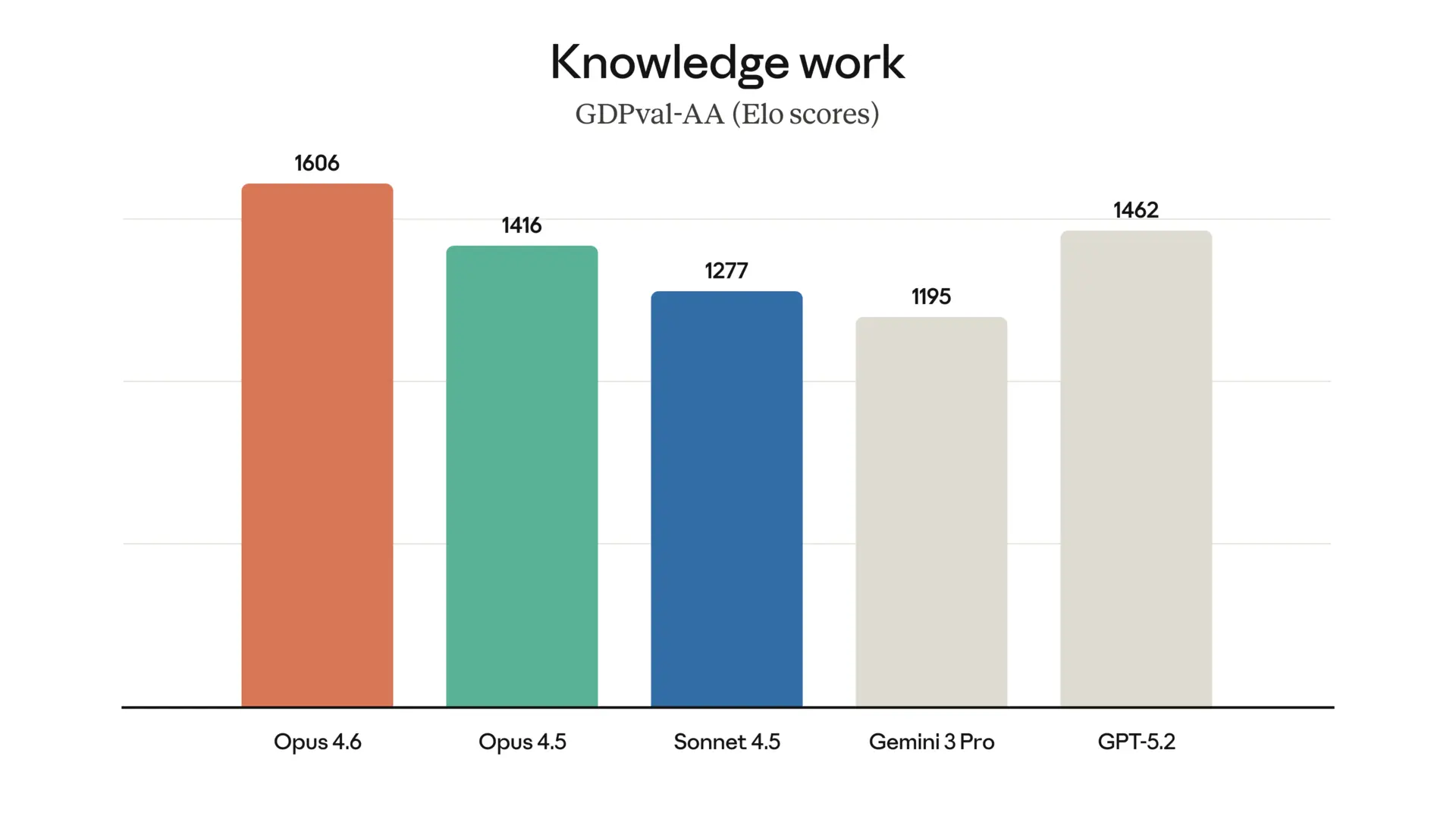
GDPval-AA (Finanz- & Rechtsanalyse): Opus 4.6 übertrifft GPT-5.2 um +144 Elo-Punkte. Das ist kein knapper Vorsprung – das ist eine andere Liga.
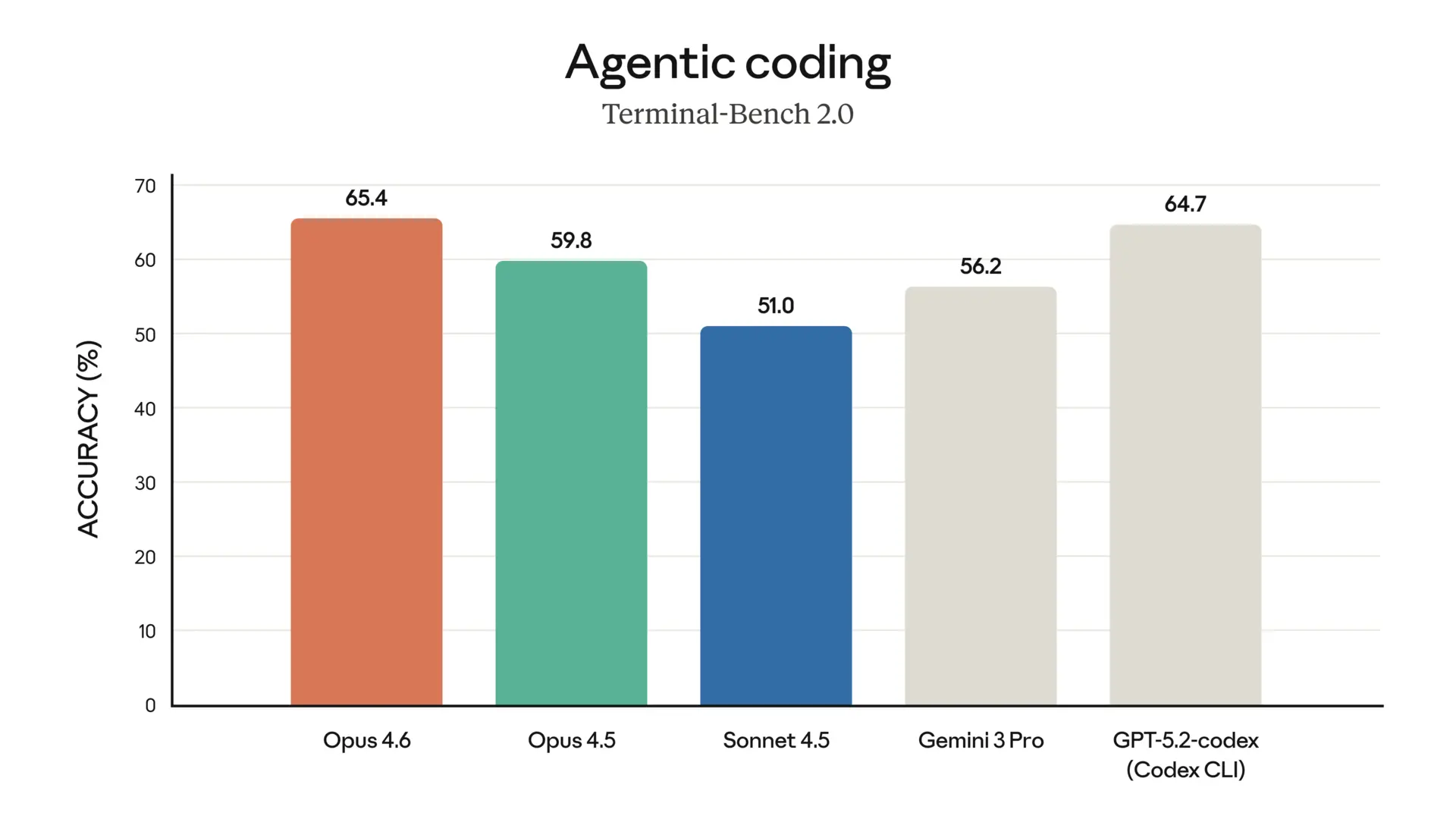
Terminal-Bench 2.0 (Agentisches Coding): Platz 1. Nicht knapp, sondern deutlich. Genau hier zählt es für uns bei Fuchsware – wenn ein Agent eigenständig Code schreibt, debuggt und deployed.
Die komplette Benchmark-Tabelle zeigt: Opus 4.6 ist in fast jeder Kategorie führend oder gleichauf mit dem Besten.
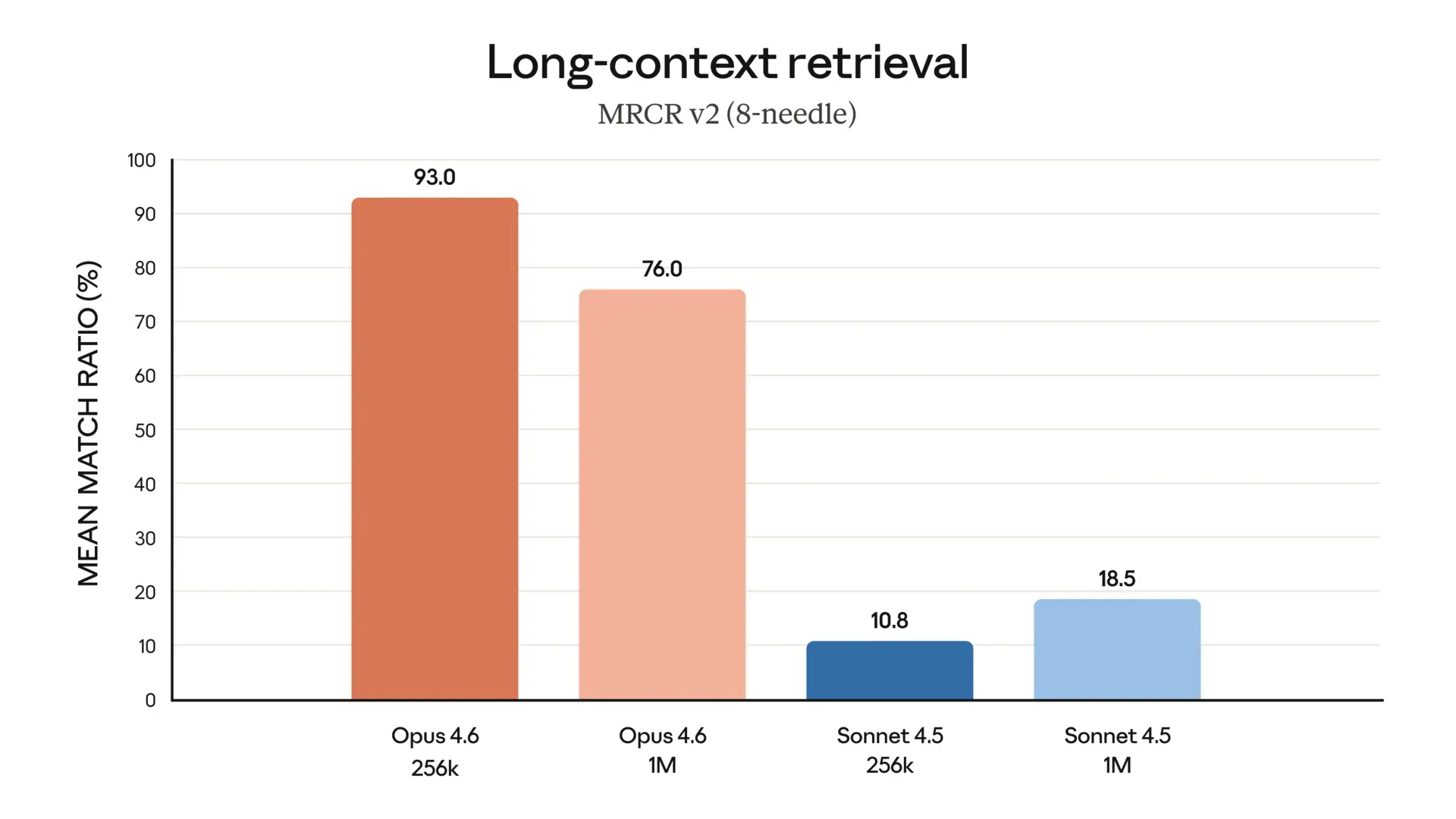
MRCR v2 (Nadel im Heuhaufen): 76% vs. 18,5% bei Sonnet 4.5. Das ist der Unterschied zwischen "Glückstreffer" und "zuverlässige Arbeit". Wenn du ein Modell brauchst, das in 100 Seiten Vertragsdokumenten die relevante Klausel findet – das ist es.
Neues unter der Haube
Neben der reinen Intelligenz bringt Opus 4.6 praktische Werkzeuge mit:
Adaptive Thinking
Claude entscheidet jetzt selbst: "Muss ich hier tief nachdenken oder reicht eine schnelle Antwort?" Das spart Token-Kosten bei einfachen Fragen und liefert maximale Qualität bei harten Nüssen.
1 Million Token Kontext (Beta)
Zum ersten Mal bei einem Opus-Modell. Das bedeutet: ganze Codebases, komplette Vertragswerke oder ein Jahr E-Mail-Verkehr – alles auf einmal im Kontext.
Context Compaction (Beta)
Bei langen Gesprächen fasst Claude den bisherigen Verlauf intelligent zusammen. Nichts Wichtiges geht verloren, aber das Modell bleibt schnell.
Was bedeutet das für unsere Kunden?
Ganz konkret: Wir setzen Opus 4.6 ab sofort produktiv ein.
Für unsere Kunden-Agenten heißt das:
- Bessere Beratungsqualität – Der Agent versteht komplexere Anfragen beim ersten Mal
- Längere Gespräche ohne Qualitätsverlust – Dank 1M Token Kontext vergisst der Agent nichts
- Niedrigere Kosten pro Interaktion – Adaptive Thinking spart Token bei Standardfragen
Für unsere internen Automatisierungen:
- Zuverlässigeres Coding – SWE-bench Verified bei 81,4%
- Bessere Dokumentenanalyse – Rechnungen, Verträge, technische Handbücher
- Weniger manuelle Nacharbeit – Der Agent korrigiert sich selbst
Wenn du wissen willst, wie dein Betrieb von Opus 4.6 profitieren kann, melde dich bei uns.
Hat dir dieser Beitrag gefallen?
Lass uns über dein Projekt sprechen und gemeinsam die Zettelwirtschaft beenden.